Strategy Meets Structure
Business Architecture for the Enterprise
Connect strategy to execution. OrbusInfinity® gives teams a unified view of capabilities, processes, and value so you can drive smarter transformation.

Common Business Architecture Challenges
Misalignment between strategy and operations creates friction, slows decisions, and limits transformation impact.
Siloed Views of the Operating Model
Capabilities, processes, and technologies are documented in disconnected tools. Without a unified model, leaders lack the cross-functional visibility needed to prioritize investment and manage change.

Strategy Disconnected from Execution
AI investments are approved in isolation. Without a clear map of how AI capabilities connect to business outcomes, prioritization is guesswork and value leaks at every stage.

Reactive, Undifferentiated Investment Decisions
Without a clear view of capability maturity and value delivery, investment decisions default to advocacy rather than evidence. High-impact opportunities are missed; low-value spend persists.


The Art of the Possible
Turn Architecture Into a Strategic Asset
OrbusInfinity gives business and IT leaders the shared model they need to align, prioritize, and act confidently.
Unified Clarity
Build a single, connected view of your operating model, linking capabilities, value streams, processes, and technologies in one place.
Aligned Investment
Assess capability maturity and map it to strategic priorities, so investment decisions are grounded in evidence, not assumption.
Stakeholder Clarity
Communicate a shared, structured view of how the business operates, bridging the gap between architecture teams, business leaders, and operational stakeholders.

Accelerated Improvement Cycles
Identify duplication, bottlenecks, and control weaknesses across end-to-end processes, then prioritize and track improvements with clear ownership, reducing cycle time and ensuring change delivers measurable results.









.svg)
Platform Capabilities
Tools to Build and Manage Business Architecture
Purpose-built capabilities that structure, connect, and activate your business architecture practice.
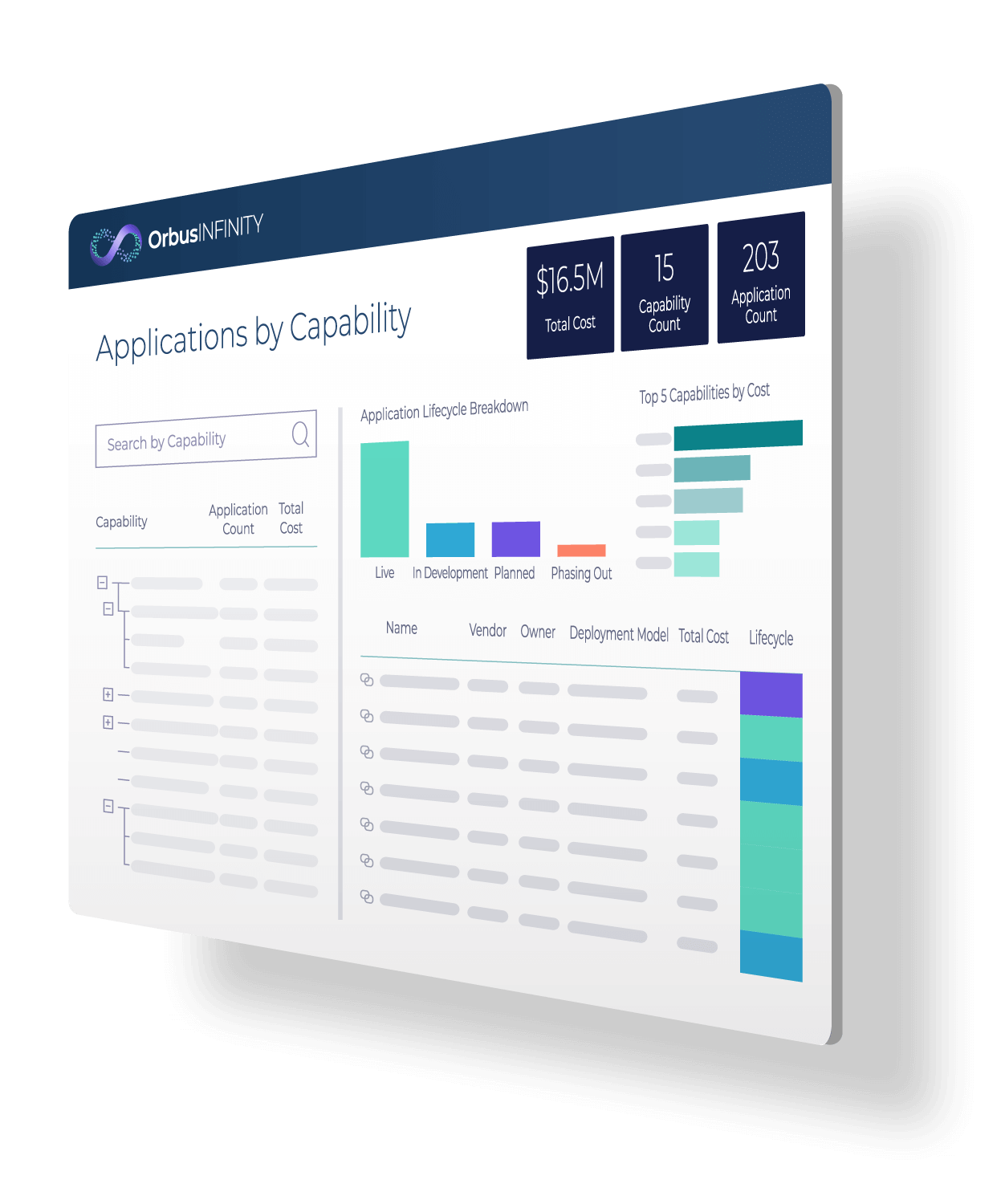
Capability Maps & Value Streams
Model business capabilities and value streams with rich, reusable objects linked to processes, roles, and technology.
Assessments & Heatmapping
Evaluate capability maturity with configurable assessments and visualize gaps and strengths through dynamic heatmaps.
Operating Model Integration
Connect business architecture to OrbusInfinity's EA platform for traceability across strategy, business, and IT.
Configurable Dashboards & Sites
Communicate architecture insights to stakeholders through tailored dashboards and shareable, role-based views.
Scenario & Roadmap Planning
Model future-state scenarios and build strategic roadmaps that link transformation initiatives to business capabilities.
Latest Success Stories

Ecobank
Ecobank enhances enterprise architecture with OrbusInfinity, improving collaboration, decision-making, transparency, and application management across its operations in 33 countries.

Global Conglomerate
A global leader in communications, automotive, and media transformed its enterprise architecture to enhance visibility, streamline operations, and drive strategic alignment.

The Mauritius Commercial Bank
MCB leveraged OrbusInfinity to transform its enterprise architecture, enabling collaboration, visibility, and business-aligned digital transformation.
Explore Further
Business Architecture Use Cases
OrbusInfinity Business Architecture spans multiple disciplines, each addressing a distinct strategic challenge.

Customer Experience
Model customer journeys, service blueprints, and persona profiles. Align experience design with value delivery so every touchpoint earns trust.

Strategy Execution
Connect strategic goals to initiatives and roadmaps, ensuring transformation stays on course.

Portfolio Planning
Align investment to business capabilities and strategic priorities with structured planning.
.svg)
Business Process Analysis
Identify inefficiencies, assess risk exposure, and understand the downstream impact of change.
Let’s Get Started
Ready to transform with confidence and make smarter decisions?
Discover how OrbusInfinity can provide total visibility, enable confident decision-making, and drive smarter transformation outcomes for your business.