
Summary: We’ve already looked at what work items an organization might want to cover while rolling out a modeling tool, and how the scope of each of them drives how large each task is. The third piece of the puzzle, before we can assemble a project plan from this, is to understand which of these tasks depends on other tasks, and in what way.
In the first post in this series, where we identified the main tasks that rolling out a tool involves, I identified three main work streams; around organization and governance of the repository, around standards and legacy models, and around metadata. We can present the structure of these three streams in the following diagram.
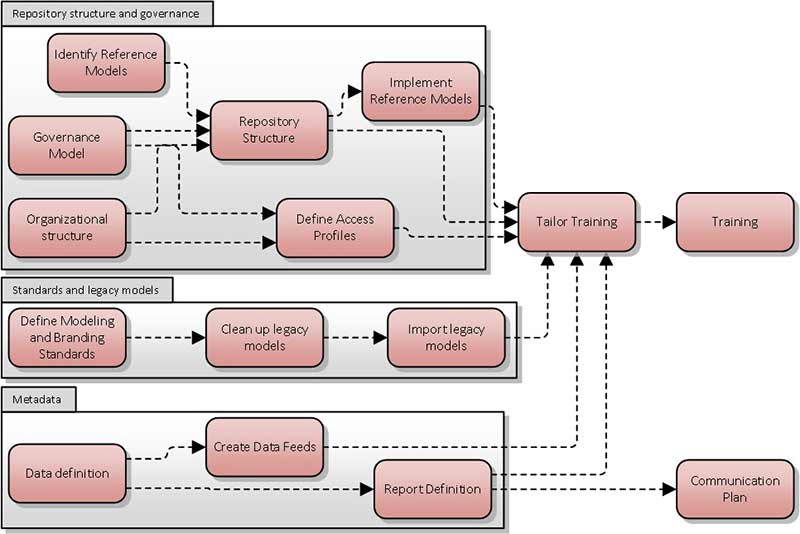
All three streams lead into the tailor training work item, which precedes only the training itself. In my experience, the training of the people who will use the tool should be the last item undertaken, as modelers should be able to log in and use the tool immediately after training. If they are forced to wait a number of days or weeks before they can implement what the training covers, then by the time they come to use the tool, half the training will have been forgotten and a refresher becomes necessary – making the original training pointless.
Now let us look at the three streams.
Implementing the reference models that you plan to use depends on the repository structure being in place: without a place to put a model, you can’t put it there.
The repository structure itself, for reasons just explained, will be affected by what reference models are being adopted… but at the same time, it depends more on the organizational structure and the governance model.
The organizational structure necessarily affects the level of co-ordination that exists; processes that are owned by the same business function naturally belong together, systems that are the responsibility of the same unit belong together. Purely to support the ability to browse information (a valuable function for an outsider wishing to understand what is there rather than search for a specific item), the repository structure should have a level of correspondence to how the teams that will be using are organized.
But the governance model also affects the structure. Most enterprise-class tools have some mechanism to keep current state from future state. The question is – whose future state? Most architecture departments make a distinction between the top-level enterprise architecture and the architecture for different segments, and solution architectures – rightly so. This does raise the question however – how closely do the segment architects co-ordinate with the enterprise architects? Do they all work off the same model? If a segment architect wants to plan a change, do they need to co-ordinate with the EA team? It all comes down to the level of co-ordination that is possible – in other words, how do changes get approved, how closely do given teams work together?
The other output from defining the organizational structure and the governance model is that it becomes very clear what access profiles need to exist – who, in what team, should have access to what?
The second work stream deals with legacy models. The reality is that to enable the analysis and reporting that a tool provides, you have to adopt and enforce a metamodel – a standard set of objects, that can relate to each other in a standard set of ways. A report that shows which servers in which locations support which applications necessarily means that you are tracking and distinguishing locations, servers and applications. Otherwise the only report you can run is “show what things do things with other things”. At the same time, the diagrams that represent the models need to use a consistent notation, a consistent way of representing data – a server should look the same no matter which diagram it is on. The combination of metamodel and notation forms a modeling standard.
So, before legacy models can be useful for analysis purposes, they need to be aligned to a modeling standard, and before you can align them to a modeling standard, you need to decide on one.
The last work stream deals with metadata. Here we consider what needs to take place to enable reporting, but also integration with other tools.
It seems obvious that both depend on a definition of metadata. You can hardly map the fields in the export format of one tool to the fields in the import format of another without having defined what those fields are. Likewise, a report that wants to see all risks with an impact of ‘high’ implies that you are tracking an impact attribute for risks.
Granted, the decision on what fields you want will be informed by what reports you intend to run, but it is a simple fact that you cannot create those reports and test them, until the fields containing the data exist.
In the last post in this series I’ll consider how this factors into a potential project plan and the roles that are involved.